 Antes de continuar con esta serie, quisiera comenzar con una nota del editor y mía en cuanto a fe de erratas. En el artículo anterior recibí varios comentarios que nos obligaron a revisar el contenido, y efectivamente, encontramos algunos errores que, afortunadamente y gracias a su aportación, tenemos oportunidad de corregir. Los errores tanto de conceptos como de redacción pueden resultar en algunas ideas malinterpretadas. A partir de esto es necesario hacer la siguiente aclaración: en el artículo anterior usamos de manera laxa “desbordamiento de pila” como traducción a buffer overflow y hay una razón para ello, no hay una palabra en español que sea traducción literal de buffer, ya que buffer (en computación) es dejar un espacio apartado en memoria para el almacenamiento de datos, el cual frecuentemente se encuentra dentro de una pila (stack) de memoria. No obstante que los buffers están dentro de pilas de memoria, es erróneo decir que realizamos un “desbordamiento de pila” cuando nos referimos a un buffer overflow. Hecha la aclaración y fe de erratas, no me queda más que decir que me siento realmente apenado por la situación y pido una disculpa sobre todo a aquellos que pensaron hallar una excelente guía en el entendimiento y aprendizaje sobre el desbordamiento de buffer, y un sincero agradecimiento a las personas que me hicieron las observaciones.
Antes de continuar con esta serie, quisiera comenzar con una nota del editor y mía en cuanto a fe de erratas. En el artículo anterior recibí varios comentarios que nos obligaron a revisar el contenido, y efectivamente, encontramos algunos errores que, afortunadamente y gracias a su aportación, tenemos oportunidad de corregir. Los errores tanto de conceptos como de redacción pueden resultar en algunas ideas malinterpretadas. A partir de esto es necesario hacer la siguiente aclaración: en el artículo anterior usamos de manera laxa “desbordamiento de pila” como traducción a buffer overflow y hay una razón para ello, no hay una palabra en español que sea traducción literal de buffer, ya que buffer (en computación) es dejar un espacio apartado en memoria para el almacenamiento de datos, el cual frecuentemente se encuentra dentro de una pila (stack) de memoria. No obstante que los buffers están dentro de pilas de memoria, es erróneo decir que realizamos un “desbordamiento de pila” cuando nos referimos a un buffer overflow. Hecha la aclaración y fe de erratas, no me queda más que decir que me siento realmente apenado por la situación y pido una disculpa sobre todo a aquellos que pensaron hallar una excelente guía en el entendimiento y aprendizaje sobre el desbordamiento de buffer, y un sincero agradecimiento a las personas que me hicieron las observaciones.
.
Memoria alta, memoria baja
La memoria de una computadora necesita un identificador con el cual, valga la redundancia, identificar un puesto en la memoria, a este identificador se le conoce como dirección de memoria, que es simplemente un número que va de 0 al 4,294,967,295, o lo que es lo mismo un número de 32 bits. Lo más usual es que este número sea expresado en hexadecimal por lo que su representación en este tipo de numeración seria 0x0000000 al 0xFFFFFFFF. Cuando se dice memoria alta se refiere a la memoria que tiene un número de dirección de memoria alto, el ejemplo por excelencia es 0xFFFFFFFF; por otro lado, cuando se dice memoria baja es obviamente lo contrario, la memoria con un número de dirección bajo, 0x0000000 por ejemplo. Es decir, a partir de un punto de la memoria, el que sea, la memoria que tenga un número de dirección de memoria menor será memoria baja, y la que tenga un número de dirección de memoria mayor será memoria alta1.
.
La memoria
Usualmente intentar hacerse una imagen o idea de la memoria puede resultar un tanto confuso debido a que en ocasiones alguien trata de ejemplificarla en una imagen con un rectángulo vertical en donde las direcciones de memoria alta están en la parte superior del rectángulo, pero luego alguien más viene y pone las direcciones de memoria alta en la parte inferior del rectángulo, o representa la memoria de manera horizontal poniendo las direcciones de memoria baja del lado izquierdo u otras veces del lado derecho, en fin, un verdadero relajo. En lo personal me gusta pensar en la memoria como un gran edificio porque así puedo hacer la comparación de las direcciones de memoria con la numeración de los pisos, donde la numeración es ascendente, así los pisos de abajo son los de direcciones bajas y los pisos más altos serán, obviamente, los de direcciones altas.
La manera en cómo se gestiona la memoria (o pisos del edificio) depende del sistema operativo, por ejemplo, en Windows la sección de memoria del Heap crece hacia memoria baja, mientras que en Linux la sección Heap crece hacia memoria alta. Podríamos decir que el dueño del edificio es el sistema operativo y por lo tanto ocupará los pisos más altos, o lo que es lo mismo las direcciones altas. Los pisos restantes son para los inquilinos transitorios, o sea, los procesos que realizará la computadora. Cada vez que se crea un proceso, el sistema operativo le otorga un espacio del edificio donde pondrá las instrucciones del proceso así como datos que sean requeridos, el espacio que pertenece al proceso lo dividirá en cinco segmentos donde cada uno cumple una función específica.
.
Un proceso en partes
Una vez que el sistema operativo otorga un pedazo de memoria al proceso, lo siguiente será cargar ese proceso en la memoria, la cual dividirá en cinco partes:
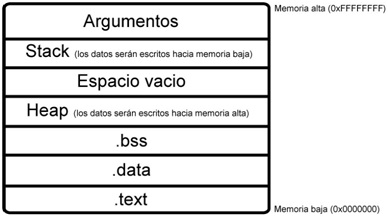
La primera se denomina “.text”2 (o también conocido como segmento de código); en esta parte se encuentra el código del programa, o si se prefiere ver de esta manera, las instrucciones de ejecución del proceso.
Si el código cuenta con variables globales que han sido inicializadas desde el momento en que el programa fue escrito (que en mi experiencia es lo más seguro), una vez que se convierte en un proceso, estas serán puestas en el segmento “.data”2. Por ejemplo, si en el código existe una variable global como “int a = 1” esta será puesta en el segmento “.data”.
Sin embargo puede ser que existan variables globales que hayan sido inicializadas como cero (p.ej. “int a = 0”) o que no hayan sido inicializadas en el código del programa y que por lo tanto obtendrán algún valor en cualquier momento después de que el programa haya sido ejecutado, o lo que es lo mismo, “en tiempo de ejecución”. Estas variables estarán en el segmento conocido como “.bss”2.
Una vez que se crearon los tres segmentos anteriores, es el turno de los segmentos Heap y Stack. Empezaré por el segmento Heap2 ya que en memoria se posiciona después del segmento “.bss” (en un sistema Linux). La verdad es que no es difícil: el segmento heap es una estructura de datos donde se almacenarán las variables que son consideradas dinámicas. Cada vez que se escribe en este segmento se empezará a tomar memoria con dirección alta y se irá escribiendo hacia direcciones de memoria baja.
Finalmente el segmento Stack2 es creado: una estructura de datos donde estarán las variables que son locales (las variables que pertenecen a una función). Como ya hemos visto, utiliza el concepto de LIFO (último en entrar, primero en salir) y no importa si las variables han sido inicializadas o no ya que como son variables locales estas se encontrarán en el segmento Stack, donde también estarán los argumentos de la función y datos de control que ayudarán a continuar con el flujo del programa. Cada vez que se introducen datos estos se irán metiendo en direcciones de memoria alta hacia direcciones de memoria baja.
De esta segmentación hay todavía un par de cosas que comentar: que es posicionada en direcciones de memoria baja, es decir, en la zona de la memoria que es designada para los procesos; y que entre el segmento Heap y Stack hay un hueco de memoria para los datos que serán puestos ahí.
Un diagrama de esta segmentación en sistemas operativos Linux sería el siguiente:
.
PUSH y POP
Existen dos instrucciones que se utilizan para trabajar en el Stack, una es Push que es la forma de agregar elementos al Stack, y la otra es Pop, que es la forma de quitar o sacar elementos del Stack.
Para entender cómo es que operan tanto Push como Pop debemos retomar a SP (Stack Pointer) y tener muy presente que siempre apunta a la dirección de memoria que pertenece a la cima o tope del Stack.
En la siguiente entrega uniremos en un ejemplo de desbordamiento de buffer todos estos conceptos que hemos visto y lo iremos analizando paso a paso.
.
.
1 Jonathan Corbet, Greg Kroah-Hartman, Alessandro Rubini, «Memory Management in Linux» en Linux Device Drivers, 3rd Ed., O´Reilly, 2005.
2 Chris Anley, John Heasman, Feliz «FX» Lindner, Gerardo Richarte, «Before you begin» en The shellcoder´s handbook: discovering and exploiting security holes, 2nd ed., Wiley Publishing, Inc. Indianapolis, 2007, p. 5.
Gastón:
Las disculpas se ofrecen, el perdón se pide, perdonar y disculpar son 2 cosas diferentes por que la disculpa viene de la persona que ofendió o se equivocó, el perdón lo otorga el ofendido, lo correcto es decir: «pido perdón u ofrezco una disculpa». Esta mal dicho: «pido una disculpa».